
Animating Encryption
Edicrypt is a small, open-source program I made while learning about encryption, python, and GUI-design with Qt. Here's the source.
It is not an encryption program, but an encryption-education program. It shows each step of various cyphers encrypting or decrypting at variable speed. This is why you can choose alphabetical encryption, as opposed to just bytewise. So one can see, for example, a->b, b->c, the Caesar cypher and more.

Check out this VIDEO to see it in action.
0. Encoding
Encoding in python is interesting. The default string in python2 is essentially just raw bytes, in python3, the default string is more abstract unicode.
>>> 'e' == '\x65'
True
>>> u'é'.encode('utf-8')
'\xc3\xa9'
So, we can see that in utf-8 encoding, 'e' is just one byte, where 'é' is two.
With practical encryption this doesn't matter as we always look at the raw bytes, but in our case where we might be interested in alphabetical encryption, this can become important. Characters in the Cyrillic alphabet are also two bytes long.
More specifically, one cannot just iterate through the string if you care about individual characters. So a lot of conversion between unicode and string takes place in the source.
Encryption blocks are used, too. This means, rather than taking it one letter at a time, taking it two letters at a time. This means one has to know where to avoid non-alphabetical characters like punctuation.
1. Qt GUI Design
Qt is for making desktop app GUIs. It works in multiple languages with similar syntax (that is, classes and their attributes have the same names) like python and c++.
Usually you will want at least one background thread to avoid the GUI stalling under longer computations. Qt has a nice class QThread, which has built in Signals/Slots to communicate between the main GUI thread and the backends.
One interesting part of GUI design in this project were the 4 main text boxes. When one selects characters in one box, the related characters are selected in the others. This means programming click-dragging over 'é' should click-drag over two characters in the byte-view box.
Scalability (text boxes expanding as the main window is expanded) is quite easy using Signals and basic geometry.
2. Encryption Implementation
This project originally started out as a way to get myself to understand more practical implementations of encryption. The actual mathematics is really quite simple number theory, though I never went into elliptic curves.
Encryption is one of the more peculiar areas of mathematics. Things closer to physics have a sort of natural "continuous" nature. Encryption, being quite closely related to human language, has a lot stranger ad-hoc techniques for cryptanalysis. In fact, ask yourself this:
Suppose you have cyphertext and the cypher, but not the key. You start trying to brute force the cyphertext by trying decryption every possibly key. When do you know you've decrypted it?
The answer to this is: "When the answer makes sense to you." When it looks like human text rather than random garbage. When the data is in the correct format. Checking if it is correct is part of what makes brute forcing via decryption take so much time. Even then, just because it looks like text, is it the right text? What if there are two ways of decrypting that data to look like English sentences?
The reason password crackers (like john the ripper) can work faster is generally passwords are smaller than text, so one can encrypt all your guesses and compare that encryption with the encrypted password itself.
3. Future Development
Originally, I'd intended to include public key cryptography and other advanced cyphers, but time ran short. Different cyphers corresponded to different classes. Cyphers that would work well with alphabetical encryption were more complex. One cannot do alphabetical encryption with certain types of encryption that may send one number to a number higher than 27 - what letter would that correspond to? This is usually the case when one is using a large prime.
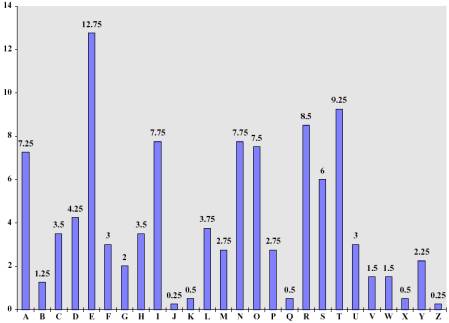
Despite including encryption blocks I didn't get around to initialisation vectors - also known as "probabilistic" encryption. Blocks and moving letters around is designed to avoid statistical attacks like letter-frequency. The letter 'a' appears more often in English than 'z', and so on. For a sufficiently long amount of text if the blocksize is 1, one can compare to a letter-frequency distribution and decrypt no matter how complicated the mathematical cypher was.
Some automated statistical attacks would also be fun to include. At the very least letter frequency analysis.
↑ Top ⌂ Home